Introduction to Linux epoll
Efficiently handling thousands of concurrent client connections is one of the most challenging aspects of server design. Over the years many approaches have been used to manage concurrent client requests. Multi-threading and multi-programming were two such prominent methods. In the multi-threading/multi-programming approach, the server creates a new thread/process for each incoming client connection. However, as the number of threads/processes increases, the system faces overhead from their switching and synchronization, which can strain CPU resources and degrade performance. To overcome this limitation, event-driven mechanisms were later used to optimize resource usage and improve efficiency. The major event-driven mechanisms include select() (introduced in the early 1980s in Unix System V), poll() (1997, Linux version 2.1), and epoll() (2002, Linux version 2.5). Both select() and poll() are system calls that allow a single process to multiplex and monitor multiple file descriptors for events such as reading or writing (In Unix-based systems, sockets are treated as file descriptors). When using select() or poll(), the programmer provides a set of file descriptors and specifies the types of events to monitor (e.g., read, write). Upon returning, select() or poll() indicate which file descriptors are ready for I/O, allowing the server to handle those specific events.
However, a key drawback of this approach is that each time select() or poll() is called, the process must pass the entire list of interested file descriptors to the kernel. The kernel then iterates through all the file descriptors to identify those that are ready, even if only a few are active. This requires the kernel to check each file descriptor individually. This approach becomes inefficient when handling a large number of file descriptors, making it unsuitable for applications that require managing high volumes of concurrent connections. Additionally, select() has a limit on the maximum number of file descriptors that can be monitored simultaneously. To address the inefficiencies of select() and poll(), an event-driven mechanism called epoll was introduced in Linux kernel version 2.5.44, released in 2002. Unlike select() and poll(), which are system calls that require repeatedly passing file descriptors to the kernel, epoll uses a set of kernel-maintained data structures to track registered file descriptors, so that the application does not have to pass the list every time through the system call interface. These data structures allow the kernel to quickly identify list of ready file descriptors on which I/O operations are possible at a given instance (from among all the registered file descriptors). Hence the kernel can pass this information to an application process that requests the kernel for list of ready descriptors. epoll is particularly efficient for handling large numbers of concurrent connections . As a result, it is widely used in modern, high-performance web servers such as Nginx.
epoll
epoll stands for event poll and is a Linux-specific construct. It allows a process to monitor multiple file descriptors and receive notifications when an event occurs on them. Essentially, it is a kernel data structure facilitating I/O multiplexing on multiple file descriptors.
epoll can be managed through three system calls, facilitating its creation, modification, and deletion. It is notably employed in Nginx, a popular web server, and it is a fundamental component of our implementation of eXpServer as well.
The Problem
The core challenge in running a network service is the speed discrepancy between the server and client networks. Typically, a server handling a request involves reading the user's request (e.g., HTTP GET), processing it, and then writing a response (e.g., an HTML page).
read user's request (eg. HTTP GET)
server process request
write a response (eg. HTML page with the requested info)Traditional servers, such as Apache, which spawn a new thread for each request, face significant hurdles when a large number of connections attempt to connect simultaneously, often leading to the infamous C10K problem.
The question arises: Can we utilize server idle time (reading and writing) more productively?
The Solution
In 2001, Davide Libenzi addressed this issue for Linux with the inception of epoll. By 2003, with the release of stable kernel 2.6, epoll became widely available.
epoll enables a single thread or process to register interest in a vast array of network sockets. A call to epoll_wait will then block until one of these sockets is ready for reading or writing. With epoll, a single thread can manage tens of thousands of concurrent (and mostly idle) requests efficiently.
epoll subtly alters the architecture of applications. Instead of a linear sequence of reading a request, handling it, and writing a response, we adopt a loop:
loop
epoll_wait on all connections
for each of the ready connections:
continue from where you left offThis approach allows you to manage multiple connections simultaneously, handling each as required without blocking. It necessitates remembering the state of each connection, performing only as much I/O as each socket can handle without blocking, and then resuming the loop with epoll_wait to monitor additional events.
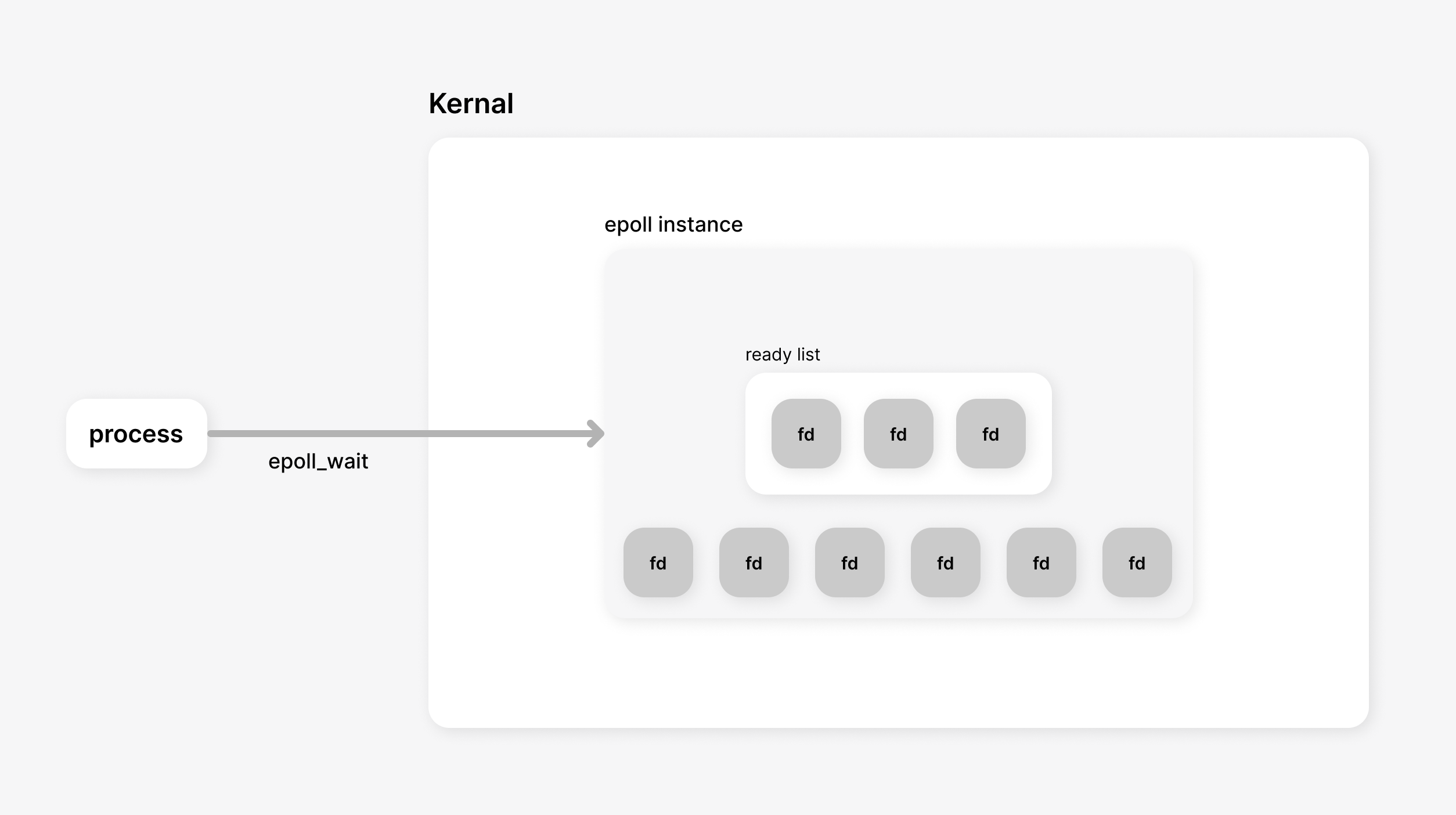
In simple words
- The process that uses epoll creates an epoll instance using
epoll_create1(). - The process can add file descriptors (FD) that it wants to monitor to the epoll instance using
epoll_ctl() - Then the server calls the
epoll_wait()function. This function will block the process till there are some events on the monitored events - If some activity is detected in the FD’s the process will unblock from
epoll_wait()and handle the events - The process goes back to
epoll_wait()when all the events are handled
To get a more in-depth look into the Linux epoll, refer Linux epoll Tutorial.