Architecture
What can eXpServer do?
Before we get into the architecture of eXpServer, let us take a look at what all things a web server is expected to do. We will take Nginx, a popular modern web server, as our reference.
Upon installation, Nginx operates as a background process. Nginx starts by reading a configuration file by the name of nginx.conf usually present at the path /etc/nginx. Based on this configuration, Nginx serves static files from a designated folder, reverse proxy requests to upstream servers, implements load balancing, and more. Here is a beginner’s guide to Nginx available for reference.
eXpServer works in a similar manner. It will take a configuration file which will describe how to serve each client request. eXpServer has two primary objectives.
- Serve static files
- Reverse proxy requests
Additional functionalities such as load balancing, gzip compression etc. will be built on top of this in subsequent stages of the project roadmap.
In order to achieve these objectives, we will implement the HTTP protocol on top of TCP utilizing the socket programming APIs provided by the operating system.
Architecture
When it comes to web servers, there are primarily 2 types of architectures:
- Multi-threaded architecture. eg: Apache
- Single-threaded, event-driven, asynchronous architecture. eg: Nginx
Let us break it down.
In a multi-threaded architecture such as that of Apache, a new thread is created to handle each incoming connection. Utilizing threads enables the server to manage multiple clients simulatneously, with the operating system taking care of thread scheduling. However, using a separate thread for every connection results in significant overhead on system resources.
Due to this limitation, most modern web servers uses a single-threaded, event-driven, asynchronous architecture. What exactly do all these terms mean?
- Single-threaded: Uses a single OS thread to operate
- Event-driven: Uses event notification mechanisms provided by the operating system (such as epoll in Linux) to efficiently monitor multiple sockets for events and determine which operations are ready for processing
- Asynchronous: Uses asynchronous I/O, which allows I/O operations to proceed without blocking and waiting for completion
Read more about the Nginx architecture here.
eXpServer uses an architecture similar to Nginx. Using the Linux epoll I/O notification mechanism, eXpServer serves clients concurrently using a single thread.
Modules
eXpServer is structured in the form of modules. A module will have functions and structs that take care of a specific task. The following figure provides a rough outline of the various modules within eXpServer:
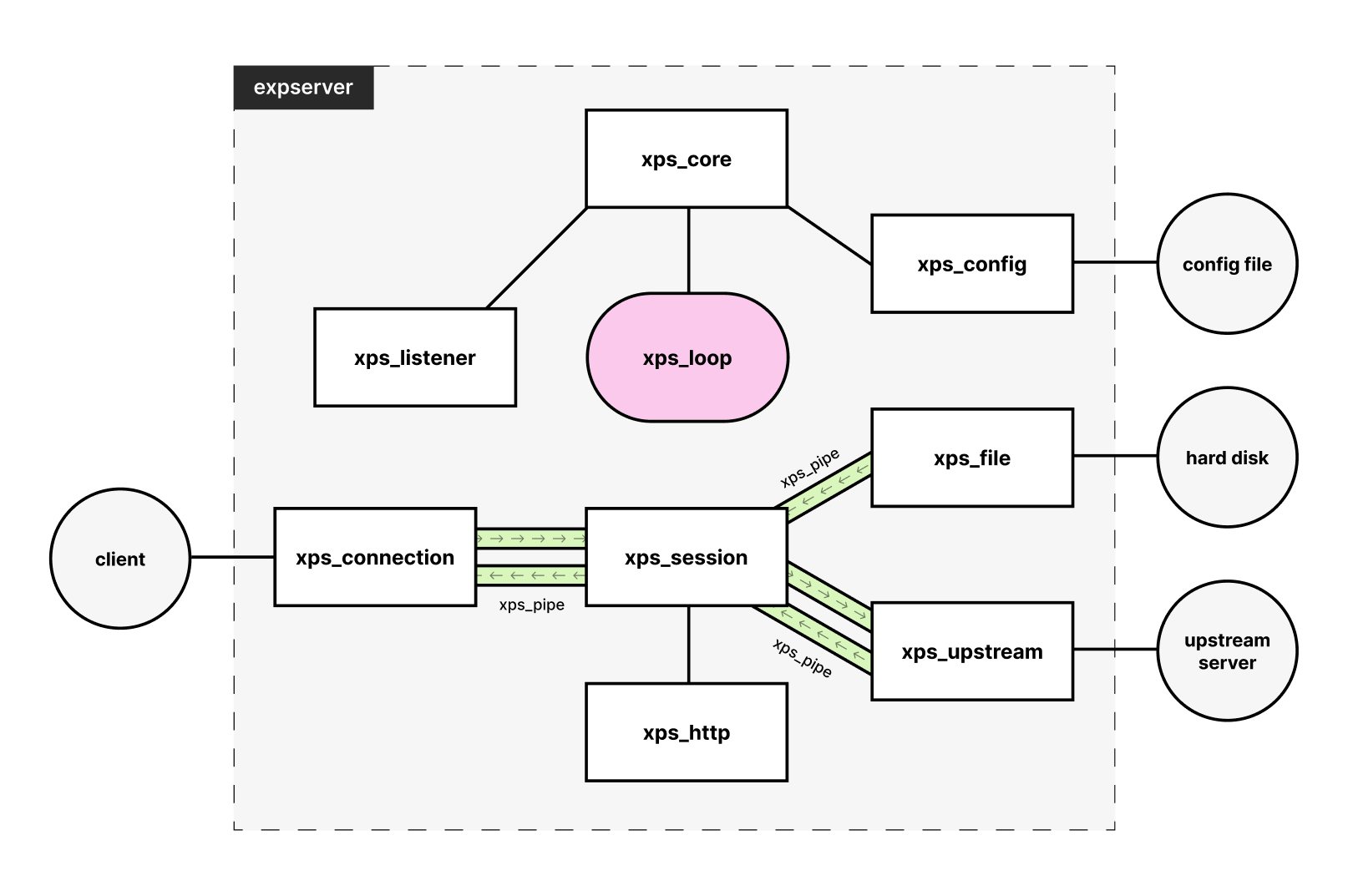
Let us go over each module one by one.
NOTE
A detailed view of the structs and functions present in each module will be explained in their respective stages along the roadmap.
xps_core
The xps_core module serves as the container to which instances of all other modules are attached. It can be thought of as an instance of eXpServer itself.
xps_loop
The xps_loop module contains the event loop. Event loop is the engine that drives eXpServer. It is implemented using Linux epoll. TCP sockets are attached to epoll to monitor for events. On receiving event notifications, the loop will handle them through callback functions. Another responsibility of the loop is to drive the xps_pipe, through which the bytes flow from one module to another (xps_pipe will be explained subsequently).
xps_config
The xps_config module is responsible for reading and parsing the configuration file, the path to which is provided as a command line argument. The configuration file will be a JSON file with a specific structure. It is parsed using parson, a 3rd party JSON parser. After parsing, it is stored in the xps_core instance as a configuration struct.
xps_listener
The xps_listener module creates a TCP listening socket and attaches it to the loop (epoll) to receive notifications for read events on the socket. Read events on the listening socket indicate that a client is trying to connect to the server. On receiving a read event, a callback function is invoked - listener_connection_handler() which will accept the connection and create an xps_connection instance for the connected client. Along with creating the connection instance, an instance of xps_session is created, which is responsible for handling the client requests according to the configuration.
xps_connection
The xps_connection module creates instances for TCP connections, be it a client or upstream server. The connection instance has handler functions which will take care of sending and receiving from the socket using the send() and recv() system calls respectively. A connection instance is ‘piped’ - attached using xps_pipe instances to an xps_session instance. These xps_pipes allow the flow of bytes between the connection instance and the session instance. The session instance will then handle the client request according to the configuration file.
xps_session
An xps_session instance is created in the previously mentioned listener_connection_handler() function at the same time a new client connection is accepted. The session instance is the orchestrator that handles the client requests. It will parse the incoming bytes from the client TCP connection using the xps_http module. Based on the parsed HTTP request, the session instance will lookup the configuration to determine whether it should serve a file or reverse proxy the request. On deciding, an xps_file instance or an xps_upstream instance is created and attached using xps_pipe to the session instance. Then the bytes flow between the client and corresponding file or upstream server through the session instance.
xps_http
The xps_http module contains 2 struct types: xps_http_req and xps_http_res . xps_http_req takes in a data buffer which is essentially a char array allocated using malloc() from the client and parses it according to the HTTP specification to create the request instance. xps_http_res takes in a HTTP response code and sets up a response instance with appropriate HTTP headers. These types also come with a serialize function which will convert the struct to a buffer that can be transmitted to the connection.
xps_file
An xps_file instance is the representation of an open file in eXpServer. Given a file path, it will open a file from the hard disk and calculate the size and MIME type of the file. The file instance is connected to the session instance using a xps_pipe to allow the flow of bytes from file to session and eventually to the client connection.
xps_upstream
The xps_upstream module takes a hostname and port as parameters, establishes a connection to the specified destination, and then returns an xps_connection instance. This connection instance is then attached to the session using xps_pipes.
xps_pipe
The xps_pipe module serves as a link between various nodes, such as xps_connection, xps_session, xps_file, and others, facilitating the controlled flow of data between them. A xps_pipe enables a unidirectional flow of bytes, with a source and a sink situated at opposite ends. The source writes data to the pipe which is subsequently read by the sink. A buffer threshold governs the pipe; if the amount of bytes within the pipe buffer surpasses this threshold, the source won’t be able write to the pipe. Pipes are driven by the event loop, aiding in the multiplexing of connections to prevent any connections from being starved.
Read more about pipes below.
xps_pipes
Pipes in eXpServer are the links that allow uni-directional controlled flow of bytes from one node to another. An xps_pipe is an instance of xps_pipe_t type and is attached to a source instance of type xps_pipe_source_t on one end and a sink instance of type xps_pipe_sink_t on the other.
Let us take a look at an example
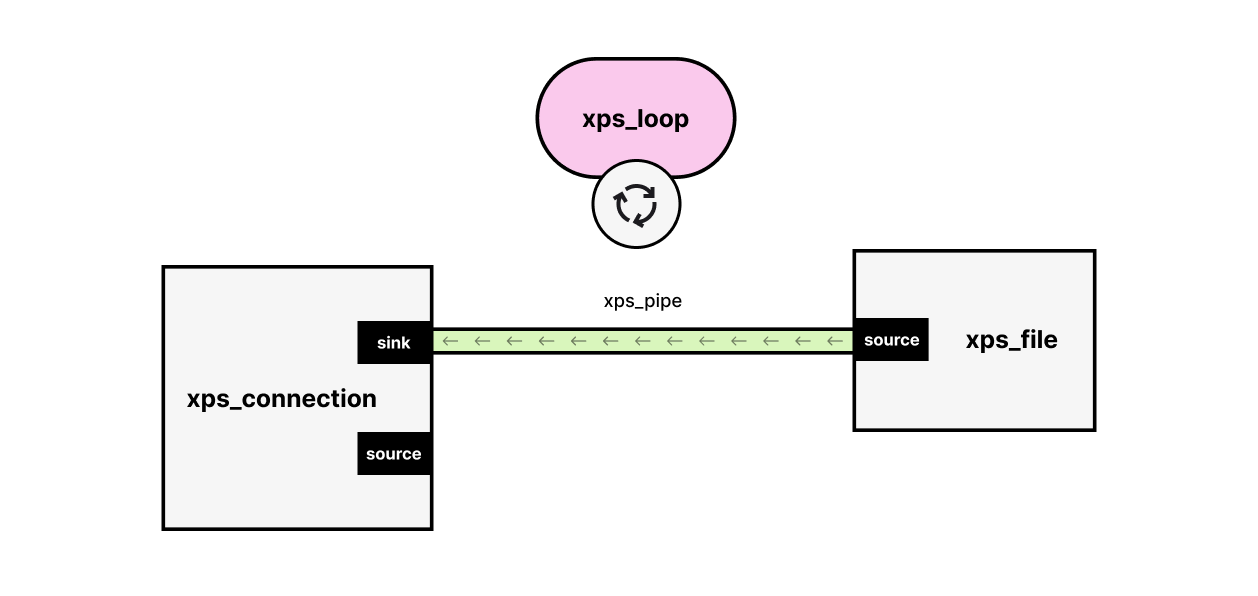
- File instance has a source with which it will write bytes from file to the pipe.
- Connection instance has both a sink and a source. Bytes that need to be sent to the socket flow into the sink and bytes that are received from the sockets flow out of the source.
In this particular example, the source of connection instance is not attached. We only want to read a file and send it to the connection.
Now let us look at how this works
- When a pipe is created, it is added to a list of pipes present in the core.
- With each iteration of the event loop, a
handle_pipes()function is invoked. - The
handle_pipes()function will iterate over all the pipes in core and checks for the following conditions- If the pipe is writable i.e. amount of bytes in pipe buffer is less than the pipe buffer threshold AND if the source is ready i.e. source has some data to write to the pipe, then a callback function -
handler_cb()on the source is invoked which will proceed to write to the pipe. - If the pipe is readable i.e. amount of bytes in pipe buffer is greater than 0 AND if sink is ready i.e. sink is available to read some data from the pipe, then a callback function -
handler_cb()on the sink is invoked which will proceed to read from the pipe. - If the pipe has no source and sink attached to it, then the pipe is destroyed
- If the pipe has a source and no sink, a callback function -
close_cb()on the source will be invoked which will notify the source that there is no sink attached to it and can destroy its instance if it wants to. - If the pipe has a sink and no source AND the pipe is not readable, then a callback function -
close_cb()on the sink will be invoked which will notify the sink that there is no source attached to it and there is nothing left to read from the pipe and hence can destroy its instance if it wants to.
- If the pipe is writable i.e. amount of bytes in pipe buffer is less than the pipe buffer threshold AND if the source is ready i.e. source has some data to write to the pipe, then a callback function -
Achieving Flow Control
Flow control is the process of managing the rate of data transmission between two nodes to prevent a fast sender from overwhelming a slow receiver.
– Wikipedia
In our case,
- If the source is writing to the pipe faster than the sink is reading it, then the pipe buffer will fill up and reach above the buffer threshold. If that happens, even if the source is ready,
handler_cb()on the source will not be invoked, thereby ‘blocking’ the source from writing to the pipe. - Similarly, if the sink is reading from the pipe faster than the source is writing to it, then, when the pipe becomes empty, the
handler_cb()on the sink will not be invoked even if the sink is ready, thereby ‘blocking’ the sink from reading from the pipe
Isolation of Logic
The problem with having a central entity, say the event loop, read directly from the file FD and write directly to the socket FD is that the logic associated with a particular module will be spread across multiple modules. This can lead to unmaintainable code and increased complexity when extending eXpServer with additional modules.
With the pipe approach, module logic is encapsulated within them with their data endpoints being exposed in the form of sources and sinks. This means that any module with a source can be attached to any other module with sink providing an easy interface for inter module communication.